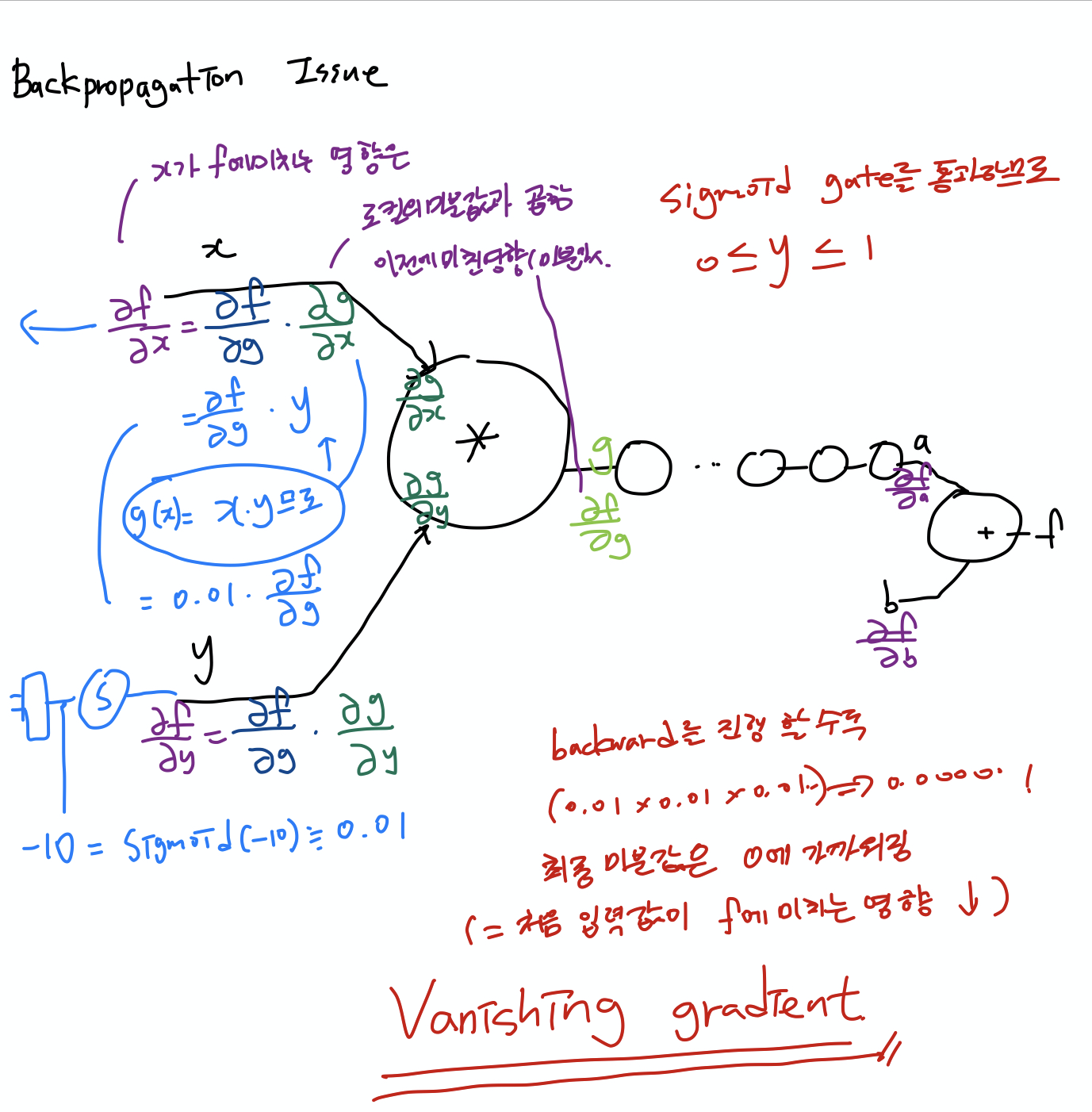
* Backpropagation Issue
- Sigmoid 함수를 사용할 경우 값이 0이상 1이하의 값으로 예측됨
- backward로 미분값을 계산할 경우 0에 가까운 값으로 곱해지기 때문에 layer가 많아질수록 처음 입력값이 최종값에 미치는 영향도가 작아짐 -> Vanishing gradient 발생

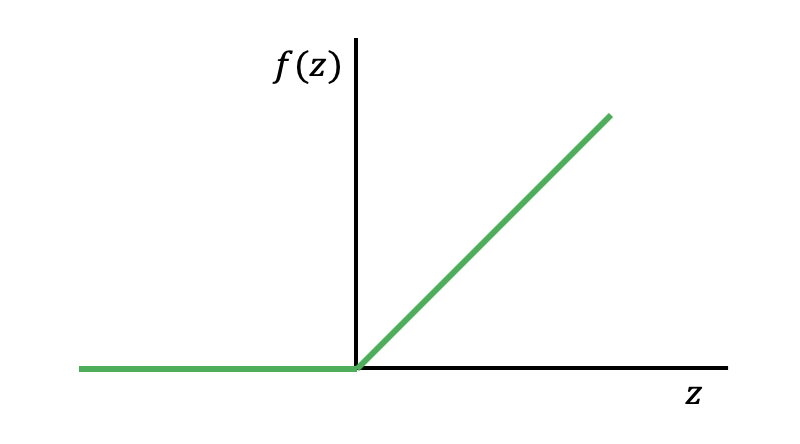
* ReLU(Rectified Linear Unit) 사용
- 0보다 작으면 inactive
L1 = tf.nn.relu(tf.matmul(X,W1)+b1)
* 초기값 설정
- W를 초기화 시킬 때 초기값을 랜덤값으로 초기화 함
- backward를 진행하면 미분값이 사라짐
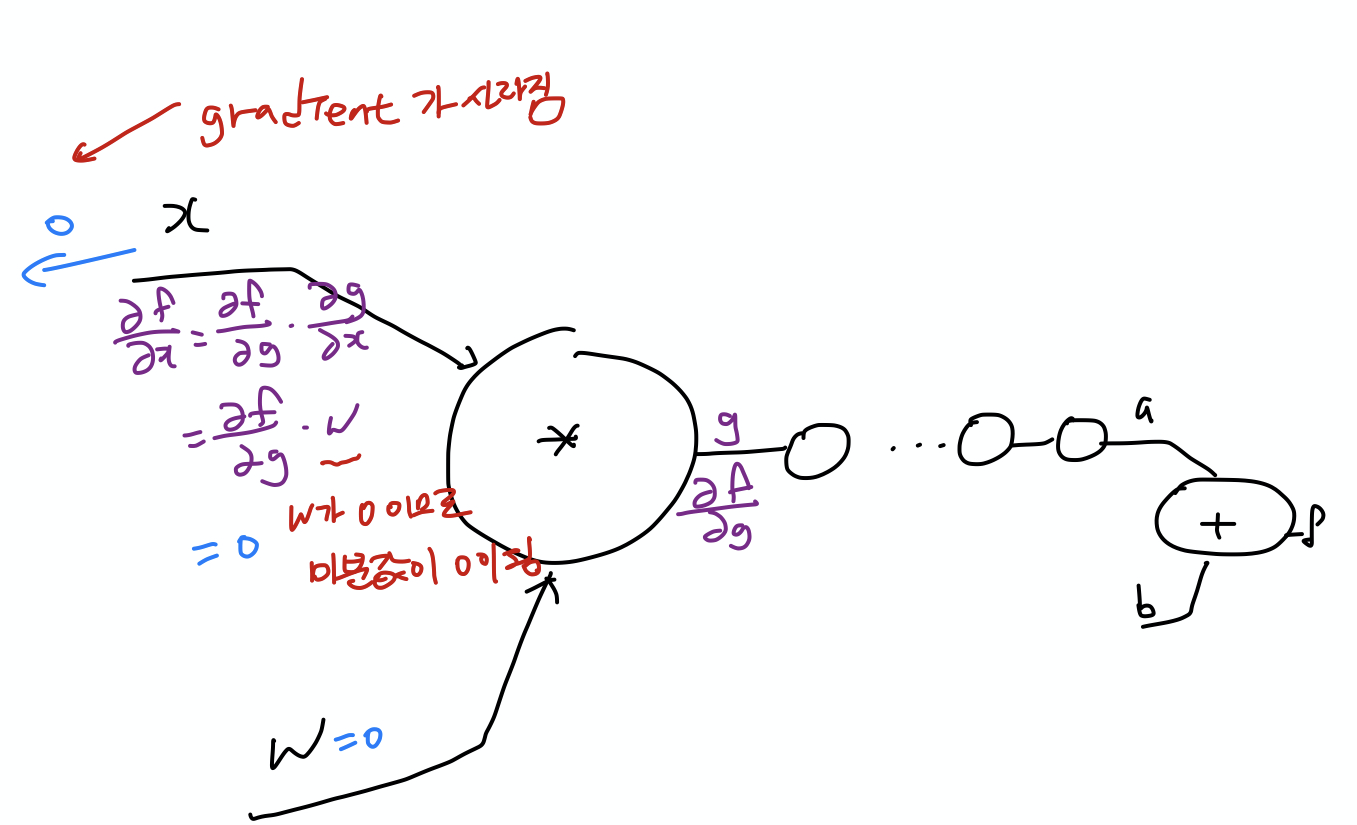
- Weight 초기값을 0으로 모두 초기화 하면 안됨
* RBM(Restricted Boatman Machine)을 사용해서 초기화 -> Deep Belief Nets 라고 부름(RBM 으로 초기값을 설정하는 NN)
- Forward 진행, Backward 하면서 생성된 x의 값이 입력된 x의 값의 차가 최소가 되도록 weight를 조절
(Backward시 x값을 예측)
* Xaiver Initialization으로 초기 값을 주면 됨
#Xavier
W = np.random.randn(fan_in, fan_out / np.sqrt(fan_in)
#He
W = np.random.randn(fan_in, fan_out / np.sqrt(fan_in/2)
* Dropout
Overfitting 이 발생하는 경우
1. Regularization
2. Dropout
- 랜덤하게 몇개의 노드를 끊어서 없애는 것
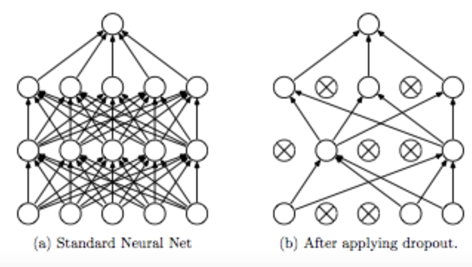
#학습할때만 dropout 시키고, 모델 사용 시 전체 사용
dropout_rate = tf.placeholder("float")
_L1 = tf.nn.relu(tf.add(tf.matmul(X,W1), B1))
L1 = tf.nn.dropout(_L1, dropout_rate)
#학습
sess.run(optimizer, feed_dict={X: batch_xs, Y:batch_ys,dropout_rate:0.7})
#평가
print("Accuracy: ", accuracy.eval({X:mnist.test.images, Y:mnist.test.labels, dropotu_rate:1})
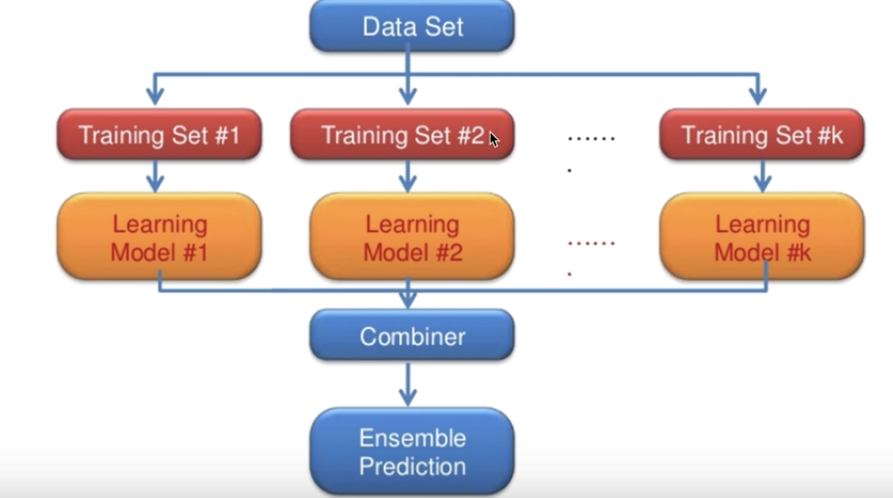
* Ensemble
- layer를 wide 하게 구성한 후 Combine 한 것
- 독립적으로 NN를 만들어서 구성
- Training Set을 같게 둘 수도 있고, 다르게 학습 할 수도 있음
- 2% ~ 5% 까지 향상됨
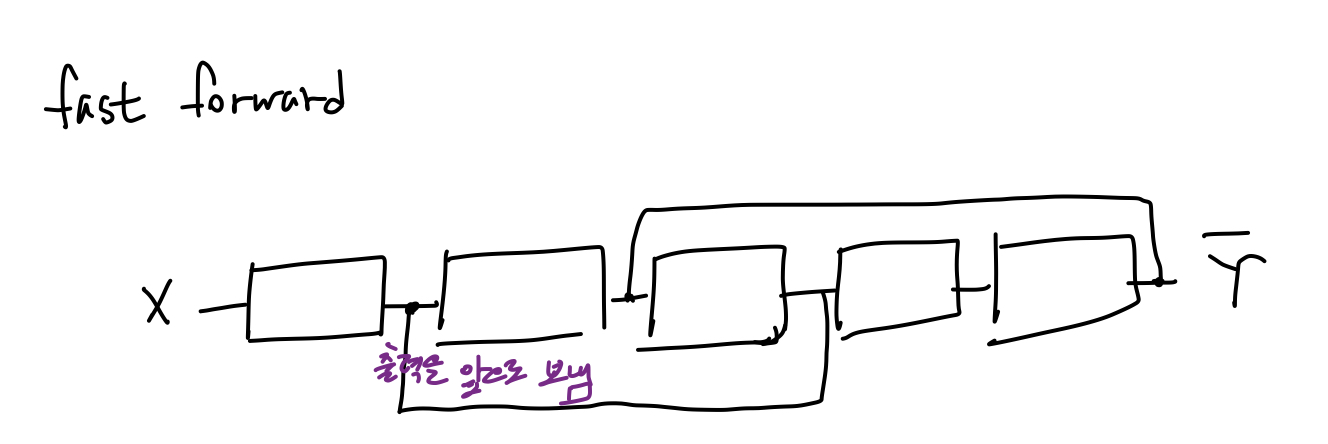
* Network Module
1. Fast forward
2. Split & merge
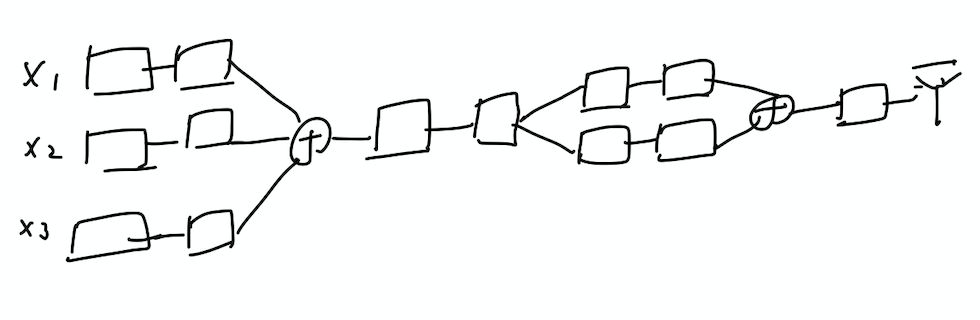
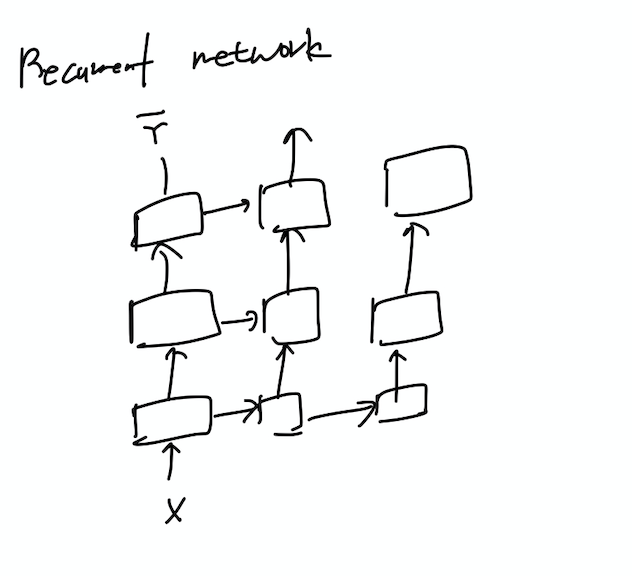
3. Recurrent Network(RNN)
실습1 - MNIST (cross_entropy with logits)
import tensorflow as tf
import matplotlib.pyplot as plt
import random
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = True)
learning_rate = 0.001
nb_classes = 10
num_epochs = 15
batch_size = 100
num_iterations = int(mnist.train.num_examples / batch_size)
X = tf.placeholder(tf.float32,[None,784])
Y = tf.placeholder(tf.float32,[None,nb_classes])
W = tf.Variable(tf.random_normal([784,nb_classes]))
b = tf.Variable(tf.random_normal([nb_classes]))
hypothesis = tf.matmul(X,W)+b
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=hypothesis, labels=tf.stop_gradient(Y)))
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
#train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
is_correct = tf.equal(tf.argmax(hypothesis,1), tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(is_correct,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
avg_cost = 0
for i in range(num_iterations):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([train,cost], feed_dict={X: batch_xs, Y: batch_ys})
avg_cost += cost_val / num_iterations
print("Epoch: {:04d}, Cost: {:.9f}".format(epoch + 1, avg_cost))
print("Learning finished")
print(
"Accuracy: ",
accuracy.eval(
session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels}
),
)
# Get one and predict
r = random.randint(0, mnist.test.num_examples - 1)
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r: r + 1], 1)))
print(
"Prediction: ",
sess.run(tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r: r + 1]}),
)
plt.imshow(
mnist.test.images[r: r + 1].reshape(28, 28),
cmap="Greys",
interpolation="nearest",
)
plt.show()

*실습 - relu, layer 구성
import tensorflow as tf
import matplotlib.pyplot as plt
import random
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = True)
learning_rate = 0.001
nb_classes = 10
num_epochs = 15
batch_size = 100
num_iterations = int(mnist.train.num_examples / batch_size)
X = tf.placeholder(tf.float32,[None,784])
Y = tf.placeholder(tf.float32,[None,nb_classes])
#W = tf.Variable(tf.random_normal([784,nb_classes]))
#b = tf.Variable(tf.random_normal([nb_classes]))
W1 = tf.Variable(tf.random_normal([784,256]))
b1 = tf.Variable(tf.random_normal([256]))
L1 = tf.nn.relu(tf.matmul(X,W1)+b1)
W2 = tf.Variable(tf.random_normal([256,256]))
b2 = tf.Variable(tf.random_normal([256]))
L2 = tf.nn.relu(tf.matmul(L1,W2)+b2)
W3 = tf.Variable(tf.random_normal([256,nb_classes]))
b3 = tf.Variable(tf.random_normal([nb_classes]))
hypothesis = tf.matmul(L2,W3)+b3
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=hypothesis, labels=tf.stop_gradient(Y)))
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
#train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
is_correct = tf.equal(tf.argmax(hypothesis,1), tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(is_correct,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
avg_cost = 0
for i in range(num_iterations):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([train,cost], feed_dict={X: batch_xs, Y: batch_ys})
avg_cost += cost_val / num_iterations
print("Epoch: {:04d}, Cost: {:.9f}".format(epoch + 1, avg_cost))
print("Learning finished")
print(
"Accuracy: ",
accuracy.eval(
session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels}
),
)
# Get one and predict
r = random.randint(0, mnist.test.num_examples - 1)
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r: r + 1], 1)))
print(
"Prediction: ",
sess.run(tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r: r + 1]}),
)
plt.imshow(
mnist.test.images[r: r + 1].reshape(28, 28),
cmap="Greys",
interpolation="nearest",
)
plt.show()

*실습 - xavier for MNIST
#W1 = tf.Variable(tf.random_normal([784,256]))
W1 = tf.get_variable("W1", shape=[784,256],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([256]))
L1 = tf.nn.relu(tf.matmul(X,W1)+b1)
#W2 = tf.Variable(tf.random_normal([256,256]))
W2 = tf.get_variable("W2", shape=[256,256],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([256]))
L2 = tf.nn.relu(tf.matmul(L1,W2)+b2)
#W3 = tf.Variable(tf.random_normal([256,nb_classes]))
W3 = tf.get_variable("W3", shape=[256,10],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([nb_classes]))
hypothesis = tf.matmul(L2,W3)+b3
*Layer 를 더 많이 만들어서 overfitting 발생
#W = tf.Variable(tf.random_normal([784,nb_classes]))
#b = tf.Variable(tf.random_normal([nb_classes]))
#W1 = tf.Variable(tf.random_normal([784,256]))
W1 = tf.get_variable("W1", shape=[784,512],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([512]))
L1 = tf.nn.relu(tf.matmul(X,W1)+b1)
#W2 = tf.Variable(tf.random_normal([256,256]))
W2 = tf.get_variable("W2", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([512]))
L2 = tf.nn.relu(tf.matmul(L1,W2)+b2)
#W3 = tf.Variable(tf.random_normal([256,nb_classes]))
W3 = tf.get_variable("W3", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([512]))
L3 = tf.matmul(L2,W3)+b3
W4 = tf.get_variable("W4", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([512]))
L4 = tf.matmul(L3,W4)+b4
W5 = tf.get_variable("W5", shape=[512,nb_classes],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([nb_classes]))
hypothesis = tf.matmul(L4,W5)+b5
* 실습 - Dropout
import tensorflow as tf
import matplotlib.pyplot as plt
import random
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = True)
learning_rate = 0.001
nb_classes = 10
num_epochs = 15
batch_size = 100
num_iterations = int(mnist.train.num_examples / batch_size)
X = tf.placeholder(tf.float32,[None,784])
Y = tf.placeholder(tf.float32,[None,nb_classes])
#W = tf.Variable(tf.random_normal([784,nb_classes]))
#b = tf.Variable(tf.random_normal([nb_classes]))
keep_prob = tf.placeholder(tf.float32)
#W1 = tf.Variable(tf.random_normal([784,256]))
W1 = tf.get_variable("W1", shape=[784,512],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([512]))
L1 = tf.nn.relu(tf.matmul(X,W1)+b1)
L1 = tf.nn.dropout(L1,keep_prob=keep_prob)
#W2 = tf.Variable(tf.random_normal([256,256]))
W2 = tf.get_variable("W2", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([512]))
L2 = tf.nn.relu(tf.matmul(L1,W2)+b2)
L2 = tf.nn.dropout(L2,keep_prob=keep_prob)
#W3 = tf.Variable(tf.random_normal([256,nb_classes]))
W3 = tf.get_variable("W3", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([512]))
L3 = tf.matmul(L2,W3)+b3
L3 = tf.nn.dropout(L3,keep_prob=keep_prob)
W4 = tf.get_variable("W4", shape=[512,512],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([512]))
L4 = tf.matmul(L3,W4)+b4
L4 = tf.nn.dropout(L4,keep_prob=keep_prob)
W5 = tf.get_variable("W5", shape=[512,nb_classes],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([nb_classes]))
hypothesis = tf.matmul(L4,W5)+b5
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=hypothesis, labels=tf.stop_gradient(Y)))
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
#cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
#train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
is_correct = tf.equal(tf.argmax(hypothesis,1), tf.argmax(Y,1))
accuracy = tf.reduce_mean(tf.cast(is_correct,tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(num_epochs):
avg_cost = 0
for i in range(num_iterations):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([train,cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob:0.7})
avg_cost += cost_val / num_iterations
print("Epoch: {:04d}, Cost: {:.9f}".format(epoch + 1, avg_cost))
print("Learning finished")
print(
"Accuracy: ",
accuracy.eval(
session=sess, feed_dict={X: mnist.test.images, Y: mnist.test.labels,keep_prob:1}
),
)
# Get one and predict
r = random.randint(0, mnist.test.num_examples - 1)
print("Label: ", sess.run(tf.argmax(mnist.test.labels[r: r + 1], 1)))
print(
"Prediction: ",
sess.run(tf.argmax(hypothesis, 1), feed_dict={X: mnist.test.images[r: r + 1]}),
)
plt.imshow(
mnist.test.images[r: r + 1].reshape(28, 28),
cmap="Greys",
interpolation="nearest",
)
plt.show()

'개발자 > 모두를 위한 딥러닝' 카테고리의 다른 글
| 12.Recurrent Neural Network (0) | 2020.02.20 |
|---|---|
| 11. Convolutional Neural Network (0) | 2020.02.19 |
| 09.XOR using Neural Networks (0) | 2020.02.18 |
| 08.Neural Network (0) | 2020.02.18 |
| 07. Application & Tips (0) | 2020.02.16 |



